- 2025年5月17日
はじめに
エンジニアの下平です。
近年、機械学習の活用事例が増えており、
「自社でも予測モデルを構築してみたい」という声をよく聞くようになりました。
そこで今回は、弊社が提供している Azure を活用したサービスの一環として、
Azure Machine Learning(Azure ML) を使った予測モデルの作り方をご紹介します。
今回はMSLearnのチュートリアル「自転車シェアリングサービスのレンタル需要予測」モデルの作成を目標にします。
事前準備
・ワークスペースの作成
予測モデルの構築や予測フローの構築等、AzureML の機能は、ワークスペースから操作します。
まだワークスペースを作成していない場合は、ドキュメントを参考に作成してみて下さい。
・コンピューティングの作成
コンピューティングとは、学習を行う際に使用するクラウド上のコンピュータの事です。
高性能であるほど学習は高速に実行出来ますが、その分コストも高額になります。
今回の例では、学習データのサイズが小さいこと、予測アルゴリズムが時系列予測のため、
「Standard_E2d_v5」インスタンスを使用しますが、更にコストの低い物を選んでも問題有りません。
・学習データの準備
自転車レンタル実績データ「bike-no.csv」をダウンロードします。
学習データの説明
学習対象のデータは、自転車レンタル実績データです。
今回のデータは、モデルを作る事が目的の為、欠損値の削除や正規化などは行ったデータを使用します。
今回はこれらの列の値から、合計レンタル数(cnt)列を予測するモデルをつくります。
| 英語の列名 | 日本語訳 |
|---|---|
| instant | インデックス(連番) |
| date | 日付 |
| season | 季節 |
| yr | 年(0 = 2011, 1 = 2012) |
| mnth | 月(1〜12) |
| weekday | 曜日(0 = 日曜〜6 = 土曜) |
| weathersit | 天気の状況 |
| temp | 気温(正規化済み) |
| atemp | 体感温度(正規化済み) |
| hum | 湿度(正規化済み) |
| windspeed | 風速(正規化済み) |
| casual | 非登録ユーザーの利用数 |
| registered | 登録ユーザーの利用数 |
| cnt | 合計レンタル数(casual + registered) |
AutoMLジョブの設定
学習ジョブの基本設定
学習を開始するための設定を行います。
自動ML > 新規の自動機械学習ジョブを選択します。
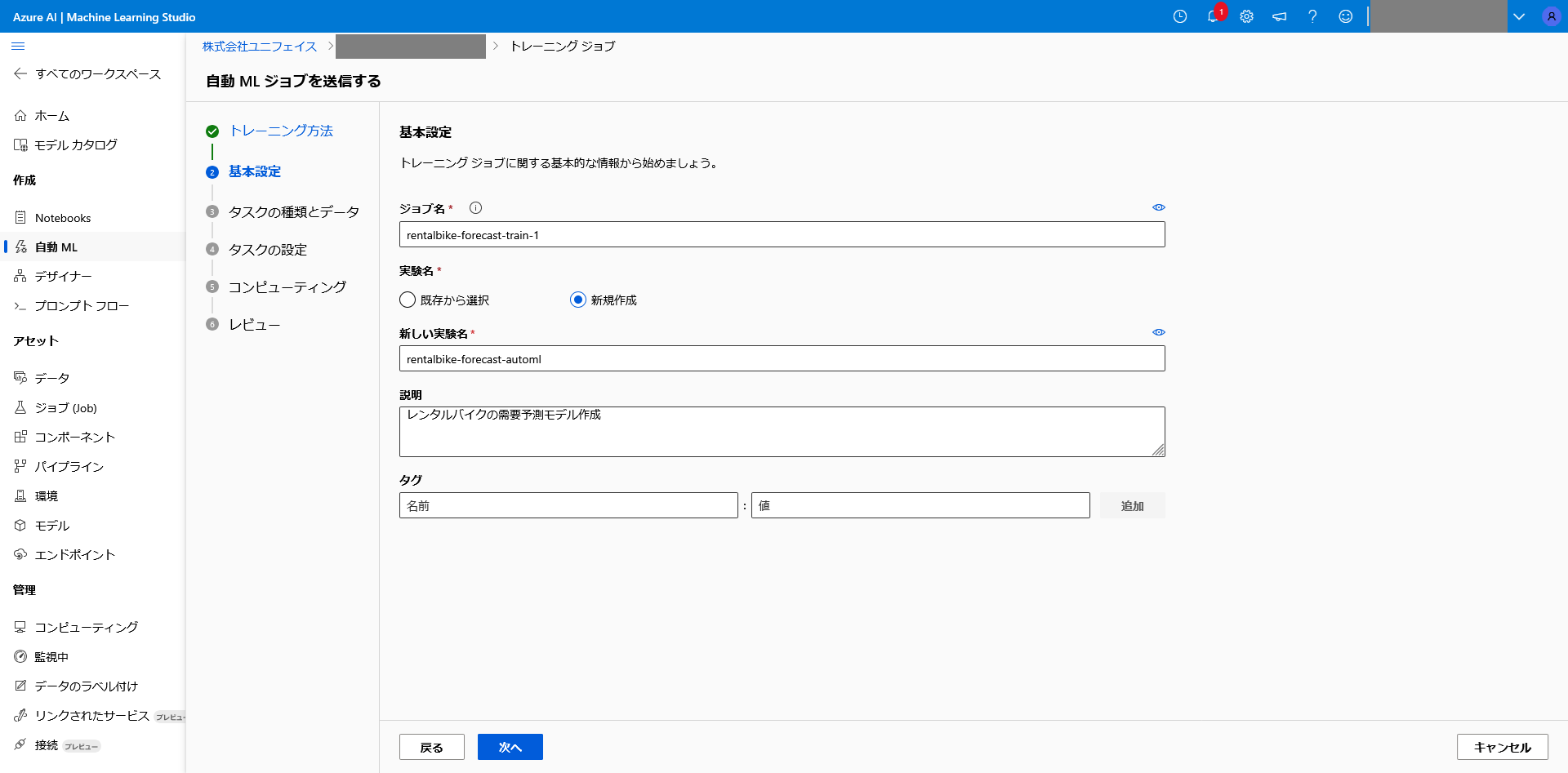
ジョブ名、実験名を設定します。
実験とはプロジェクト単位で作成するもので、今回はレンタルバイク需要予測が目的なので、
「rentalbike-forecast-automl」と設定しました。
ジョブとは各作業毎の単位で作成され、今回はモデルの学習の為、「rentalbike-forecast-automl」と設定しました。
学習データの設定
学習データの基本設定
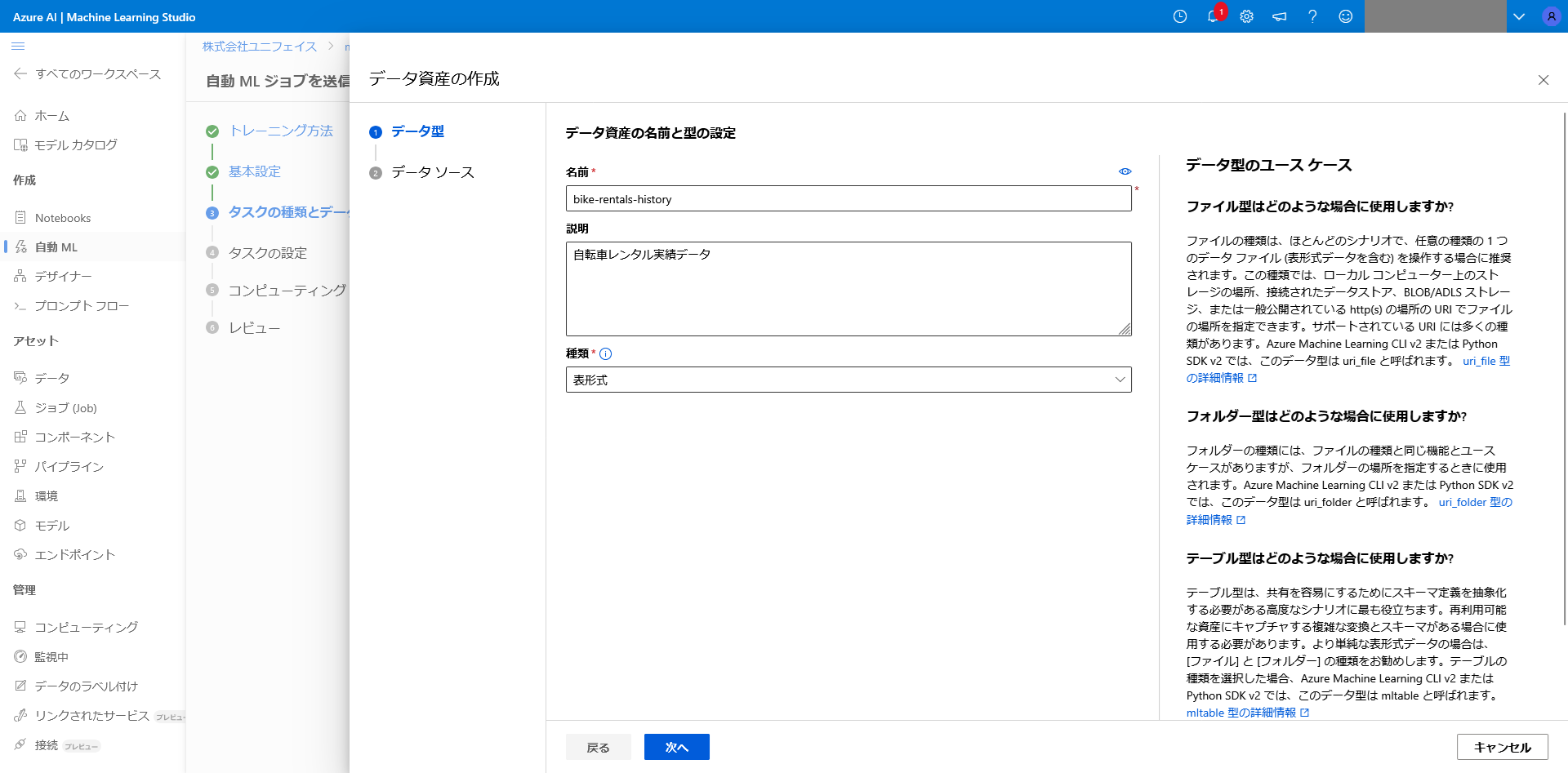
学習に使用するデータの設定を行います。
今回は、ローカルのファイルをAzureに保存して、学習に使用できるように設定します。
学習データの名前を設定、後から見たときに何のデータか判断できるように説明を記載します。
種類についてはAutoMLを使用するため、表形式を選択します。
ファイルアップロード
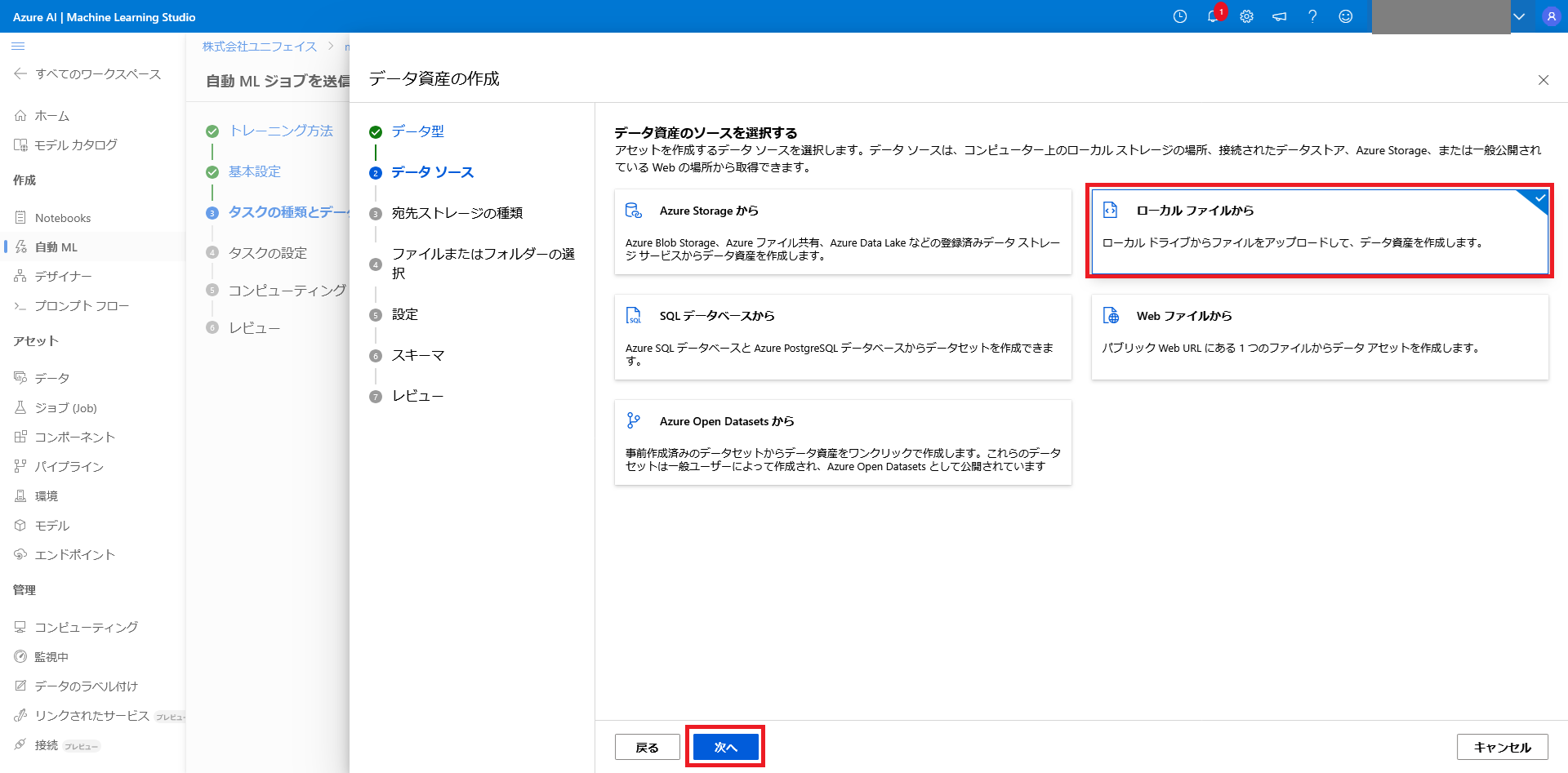
学習に使用するデータをアップロードします。
今回はローカルファイルをアップロードするので、「ローカルファイルから」を選択します。
次に「ファイルまたはフォルダーをアップロードする」を選択し、冒頭でダウンロードしたファイル「bike-no.csv」を選択します。
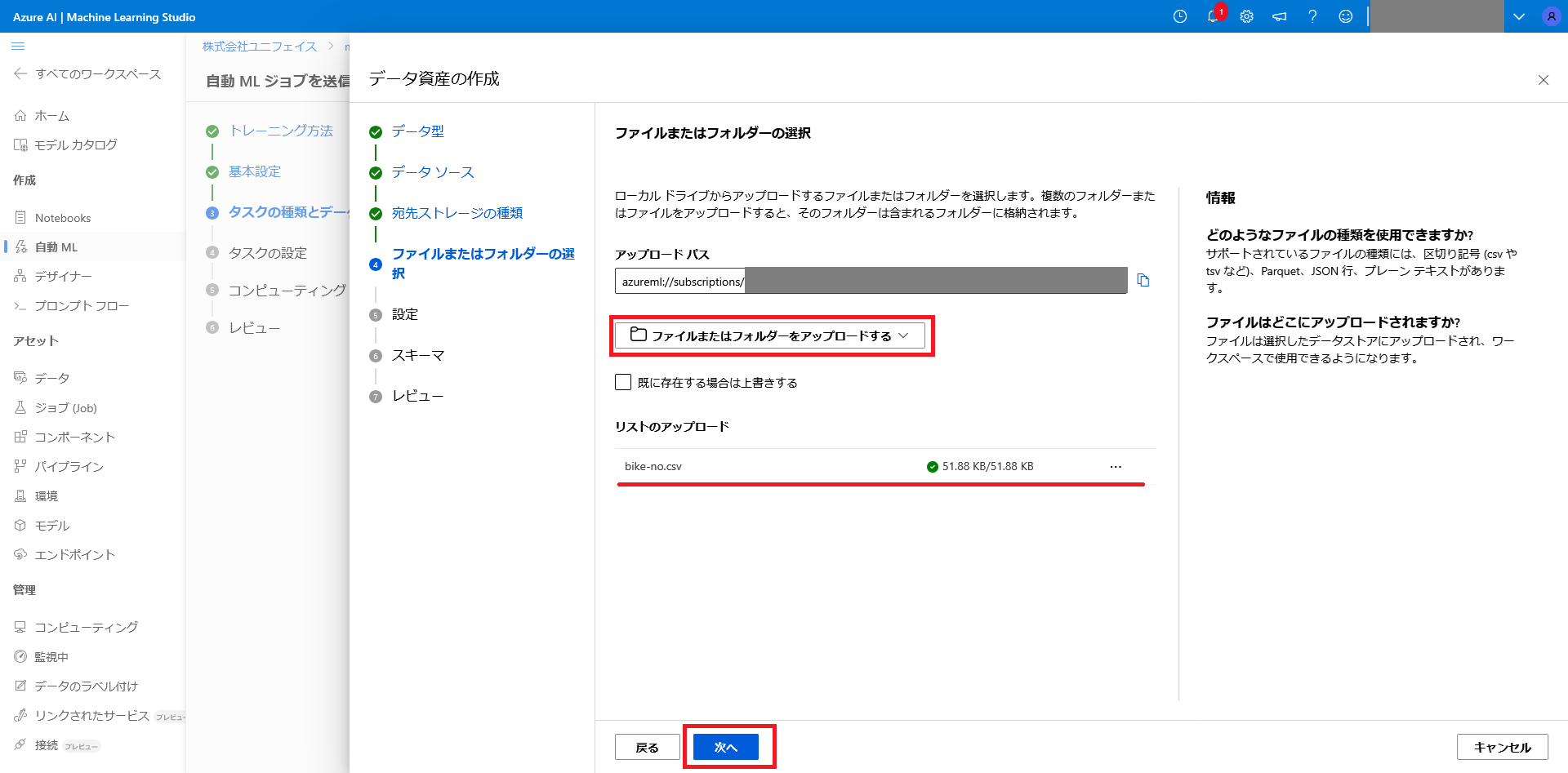
正しくアップロードできると、リストのアップロードという項目にファイル名が表示されます。
ファイルの設定
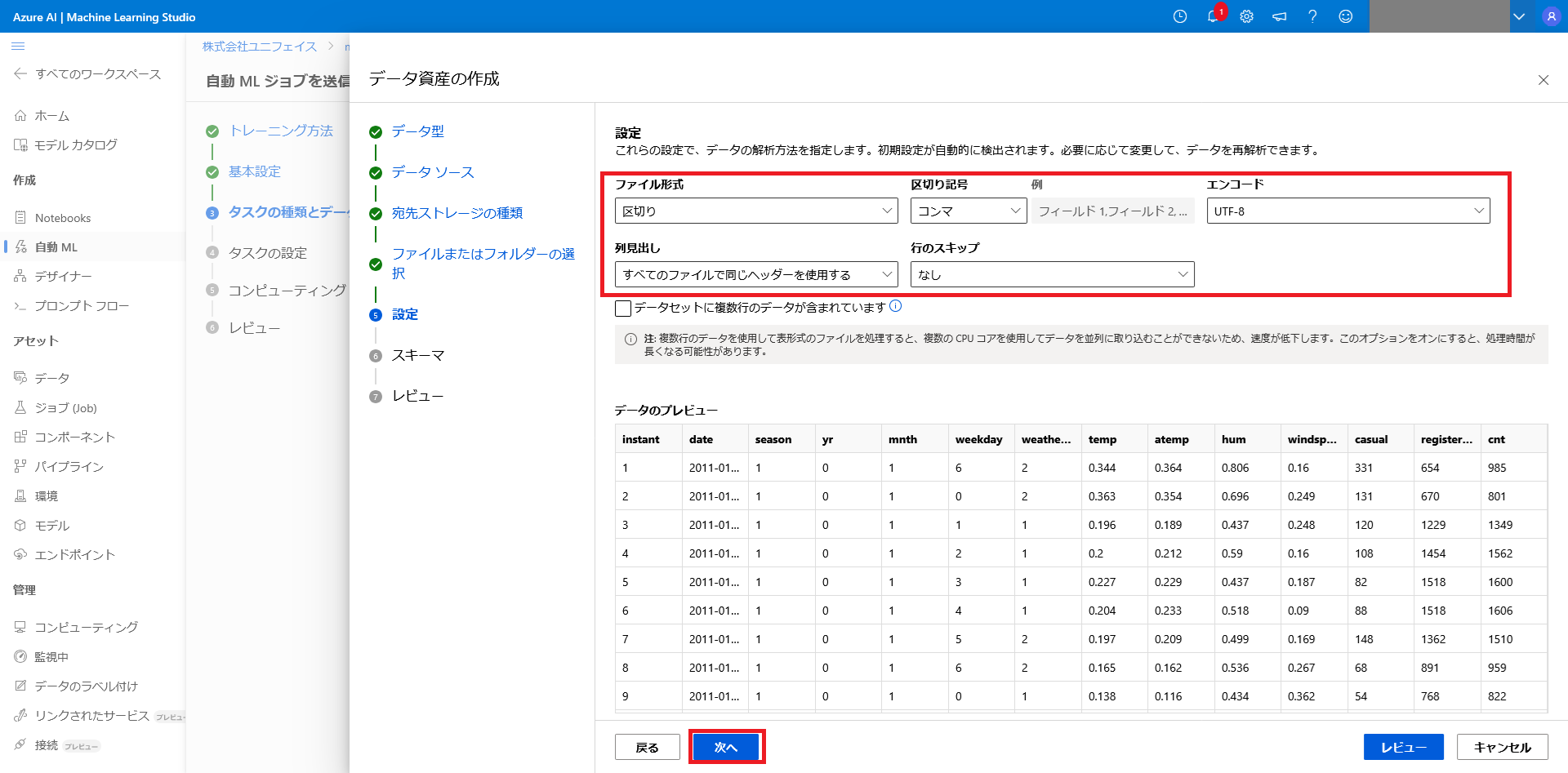
データの形式、学習に使用する列、列毎の型を設定します。
今回は UTF-8 の CSV を読み込む為、赤枠の通り設定します。
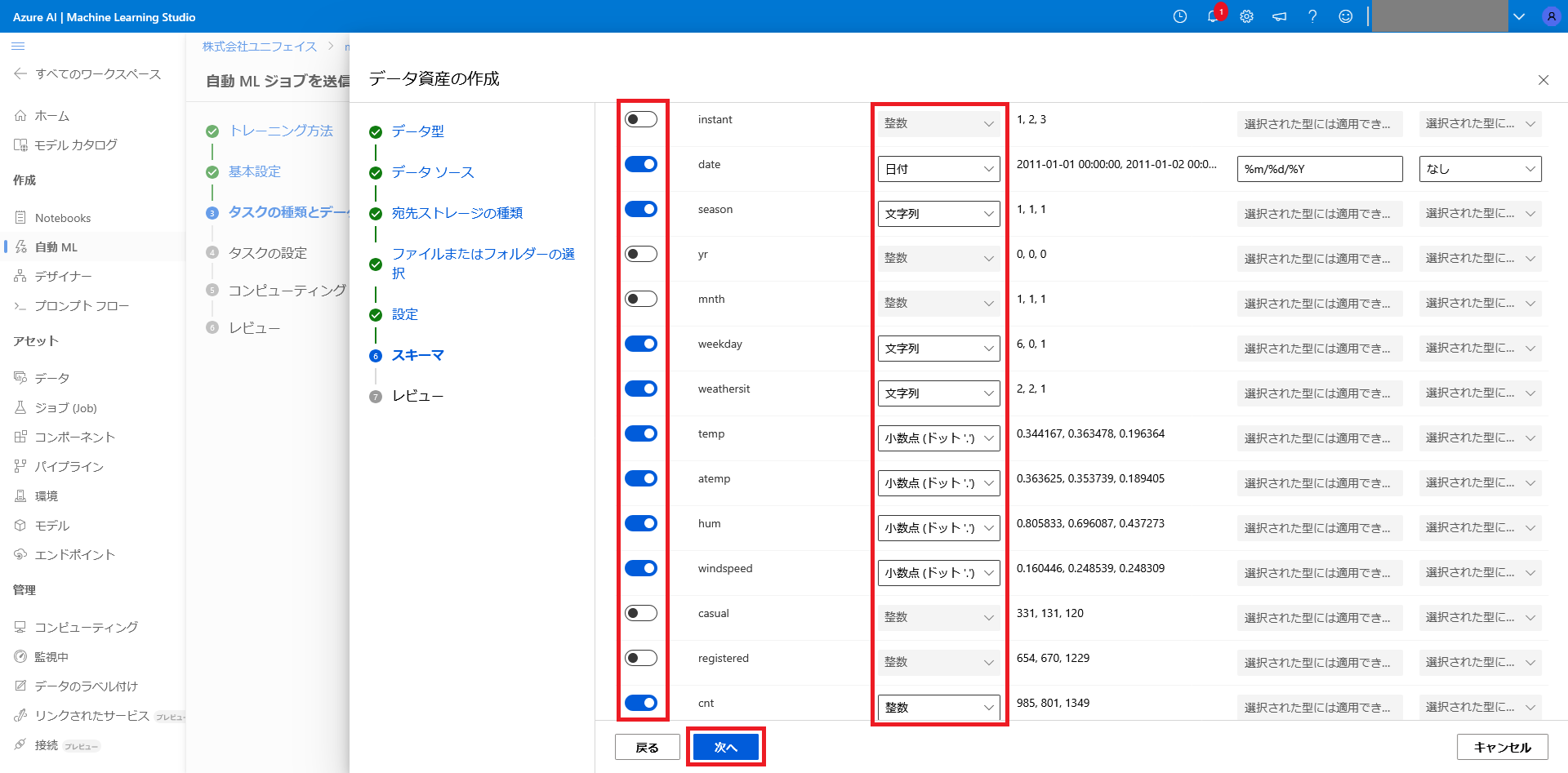
次に、学習に使用する列を設定するため、画像赤枠の通りにトグルを設定します。
今回は、日付を使用した時系列予測を行う為、dateを使用、yrやmnthはすでに情報として含まれている為、不使用とします。
また、本例の答えに相当する「cnt」列は、casual列とregistered列の合計値であり、
合計値が分かれば十分なので、casual, registered列は不使用とします。
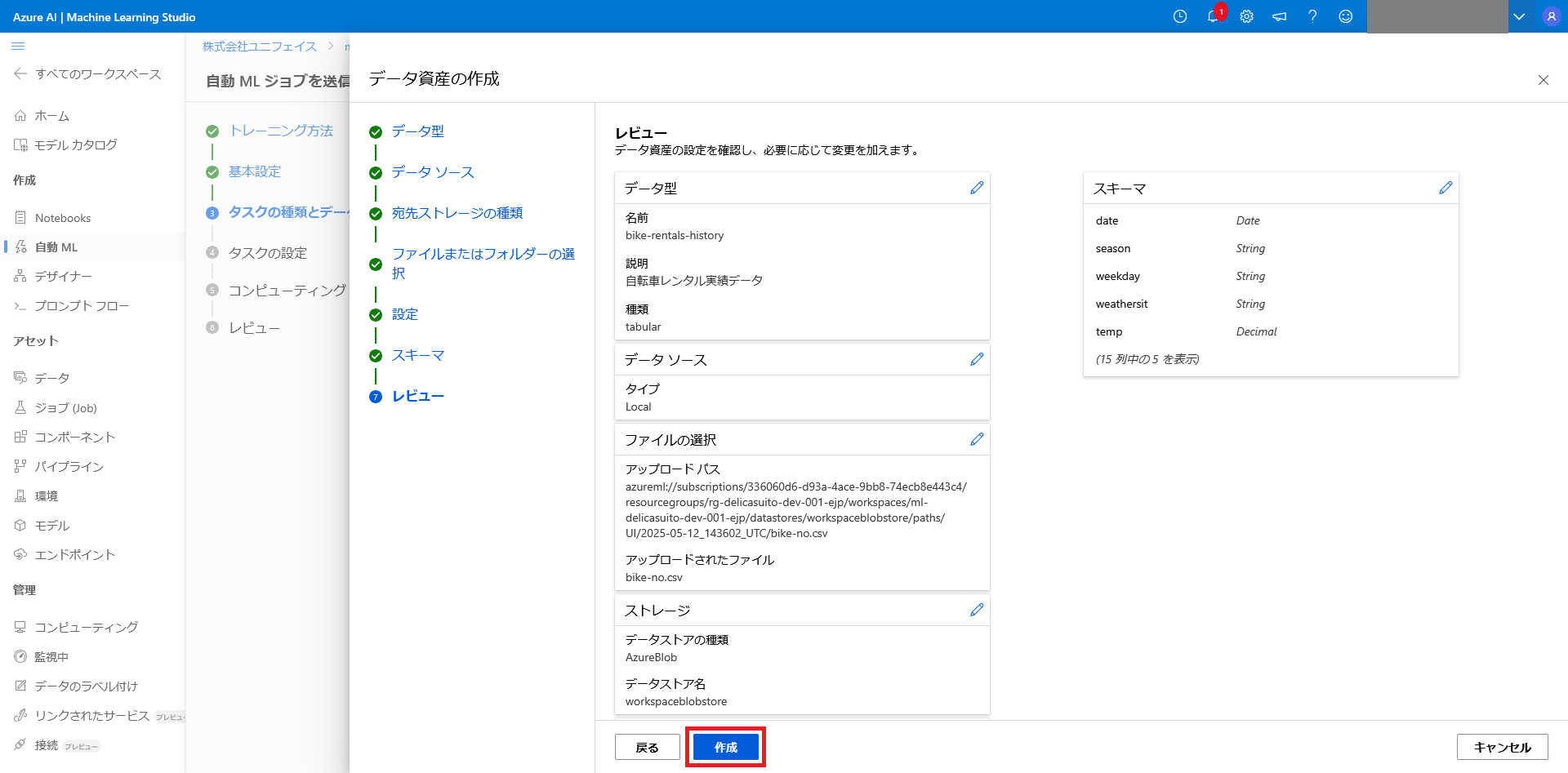
最後に、設定に誤りが無いか確認を行い、作成を選択してデータを登録します。
タスクの設定
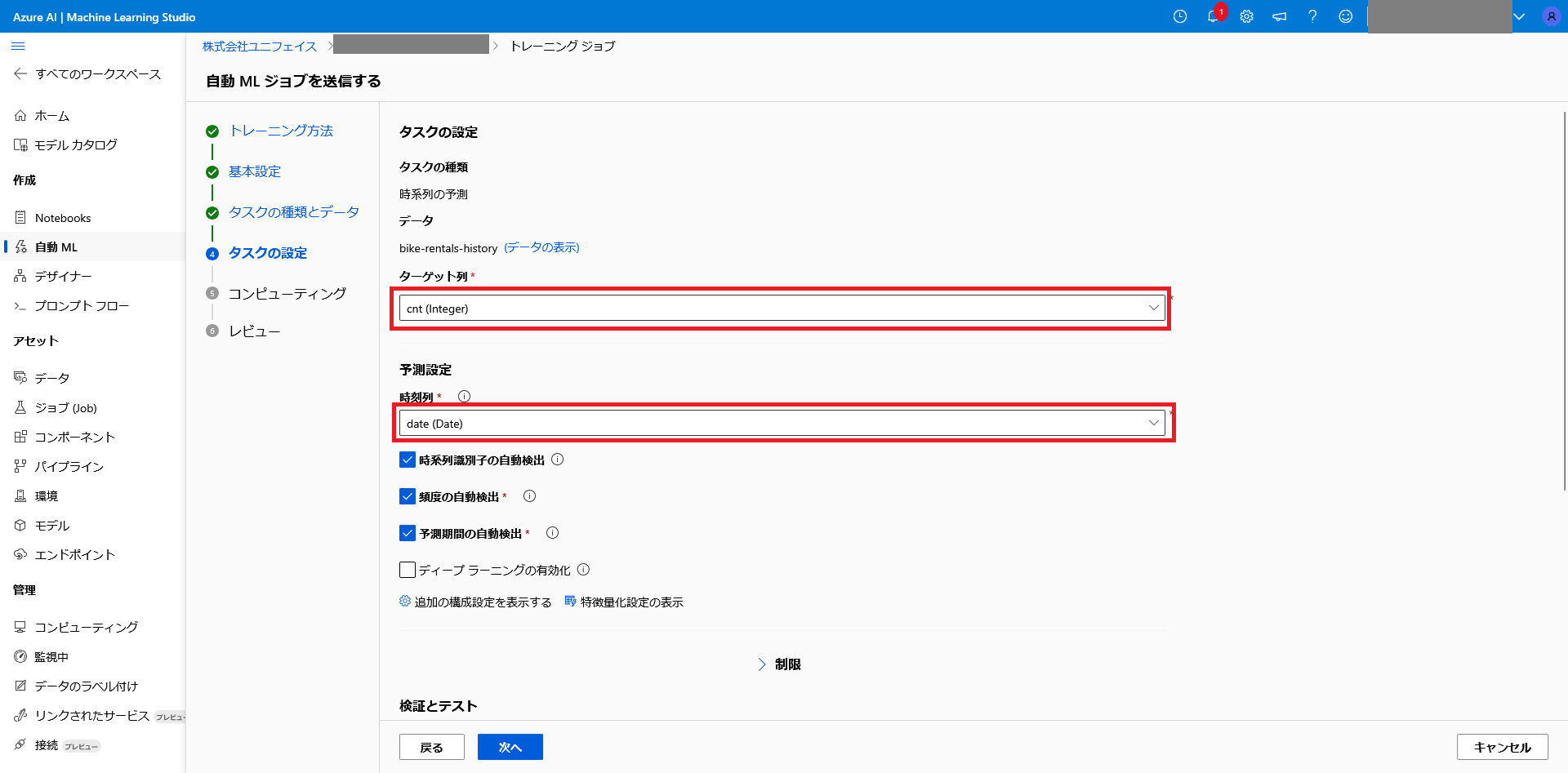
予測対象を設定します。
ターゲット列は cnt 列、時系列は date 列を指定します。
以上の設定から、今回のモデルは、時系列「date」列と季節、曜日、天気の状況、気温、体感温度、湿度、風速から、レンタルバイクの需要を予測するモデルとして作成することが出来ます。
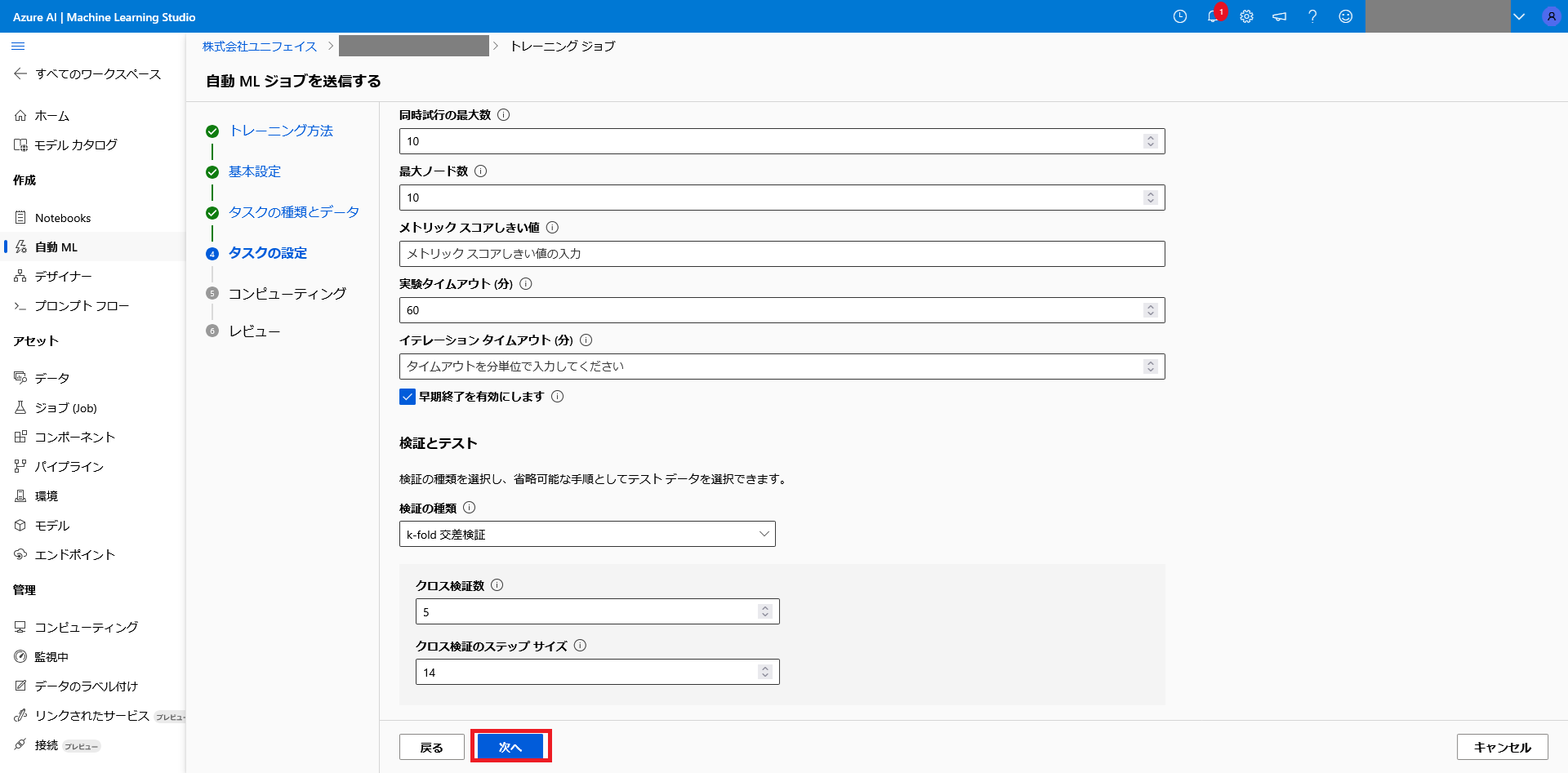
学習の進め方に関する設定を行います。
特に設定しておいた方が良い項目について説明します。
同時試行の最大数:
同時に並列で実行できる学習数の上限です。分散して学習できるため、トータルの学習時間が短縮されます。
実験タイムアウト:
実験に掛けられる最大時間を設定します。
設定時間に達すると、自動で実験が終了します。
早期終了:
モデルの改善が止まったときに、学習を自動で終了する設定です。
学習の後半では、予測精度が上がらなくなって来ますが、この設定をしておくことで、自動で学習を終了することができ、時間短縮が可能です。
コンピューティングの設定
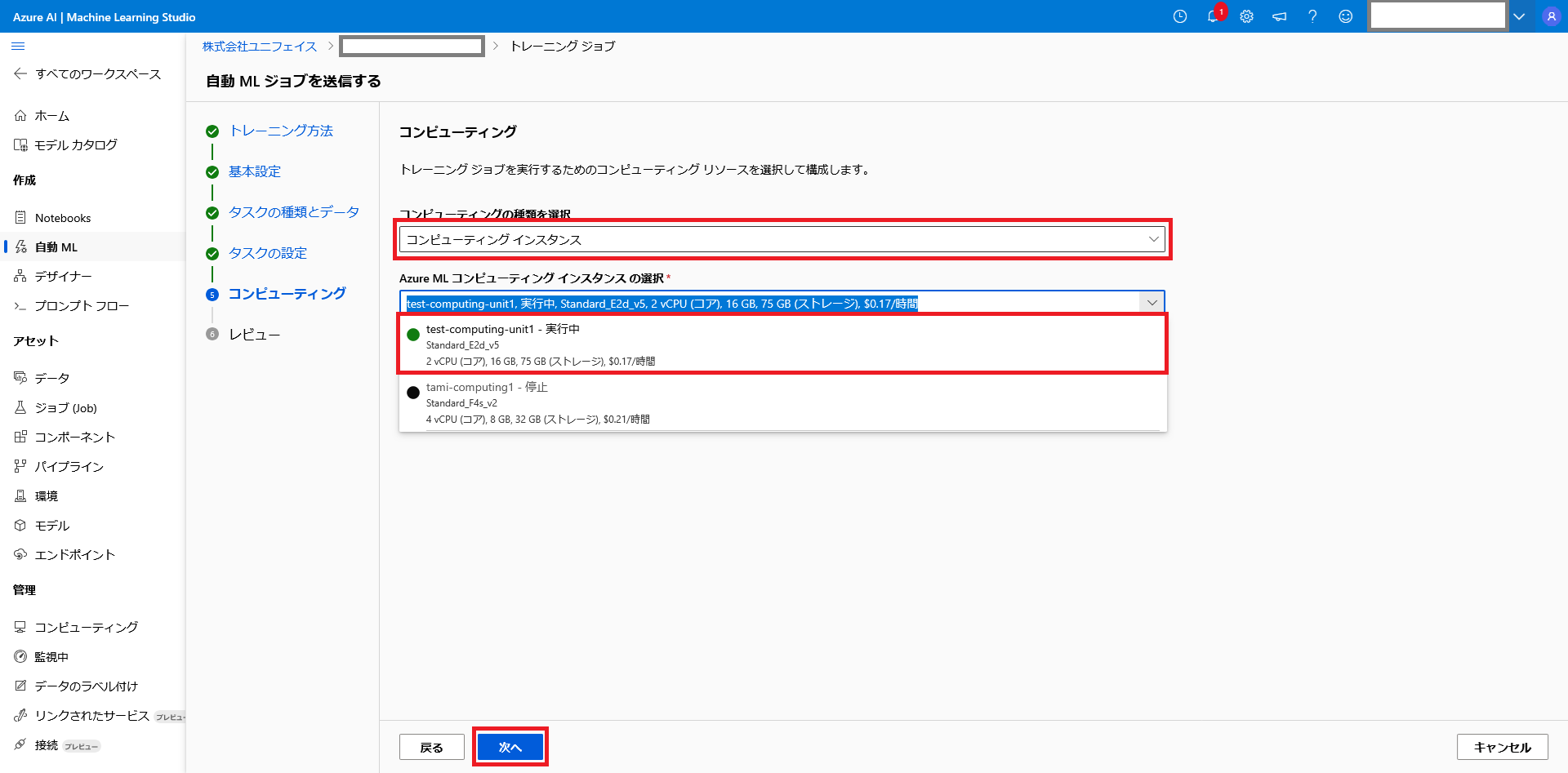
学習に使用するコンピューティングリソースを選択します。
今回は、事前準備で作成済みのリソースを選択します。
ここで、選択するコンピューティングリソースが実行中で無ければ選択出来ないので注意して下さい。
AutoML ジョブの最終確認
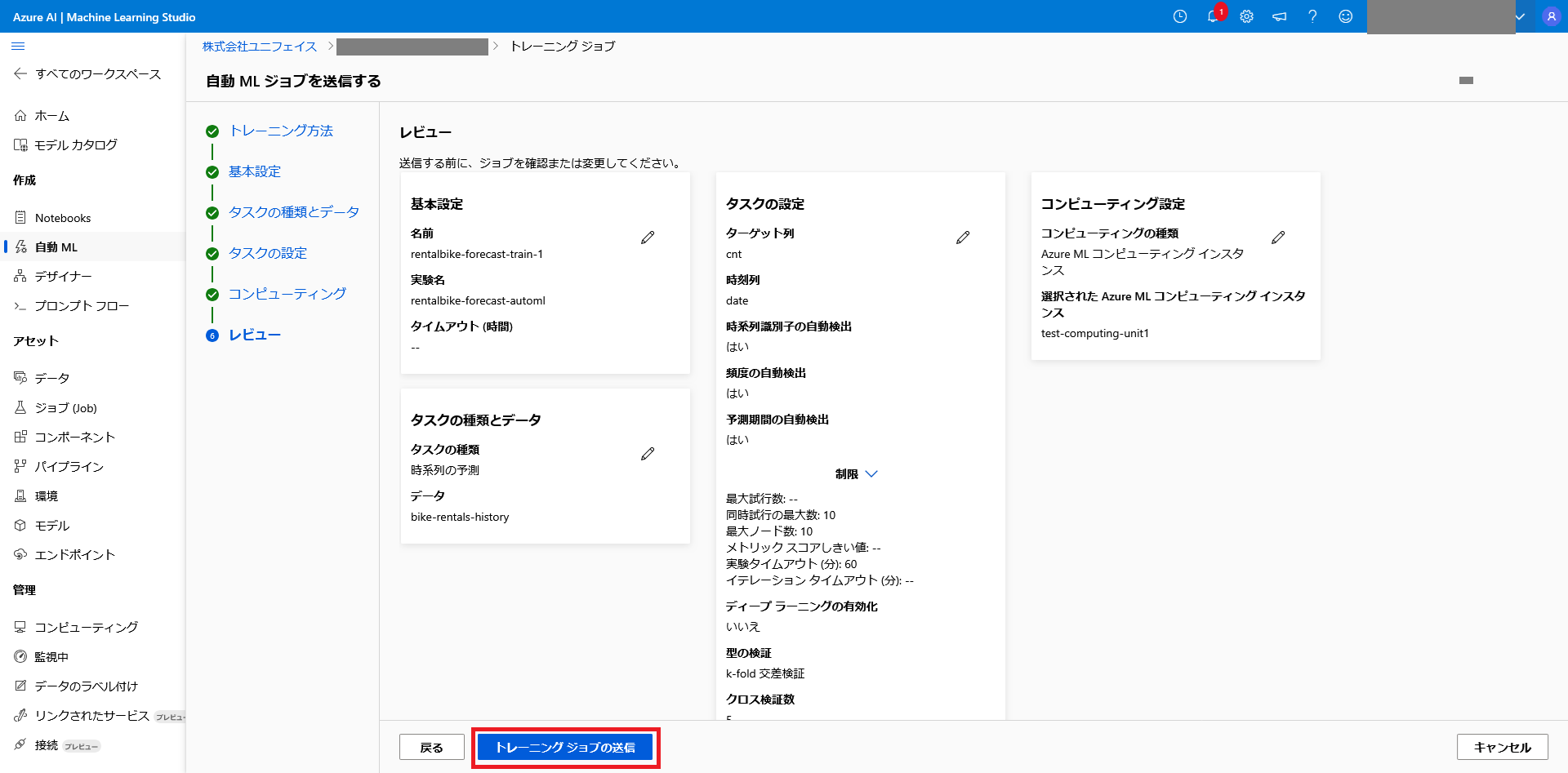
これまでに設定した内容が表示されます。
各項目が正しく設定されていることを確認して、「トレーニングジョブの送信」を選択することで
学習が始まります。
AutoML ジョブの進捗確認
画面左のペイン 自動 ML を選択し、今回作成した AutoML ジョブを選択すると、
現在のジョブの状態が表示されます。
画面の場合、「実行をセットアップしています」と表示されており、AutoML を始めるための準備中である事が分かります。
学習が完了した場合は「完了」、エラーが発生した場合は「エラー」として表示されるので、
適宜確認してみてください。
完成したモデルの確認
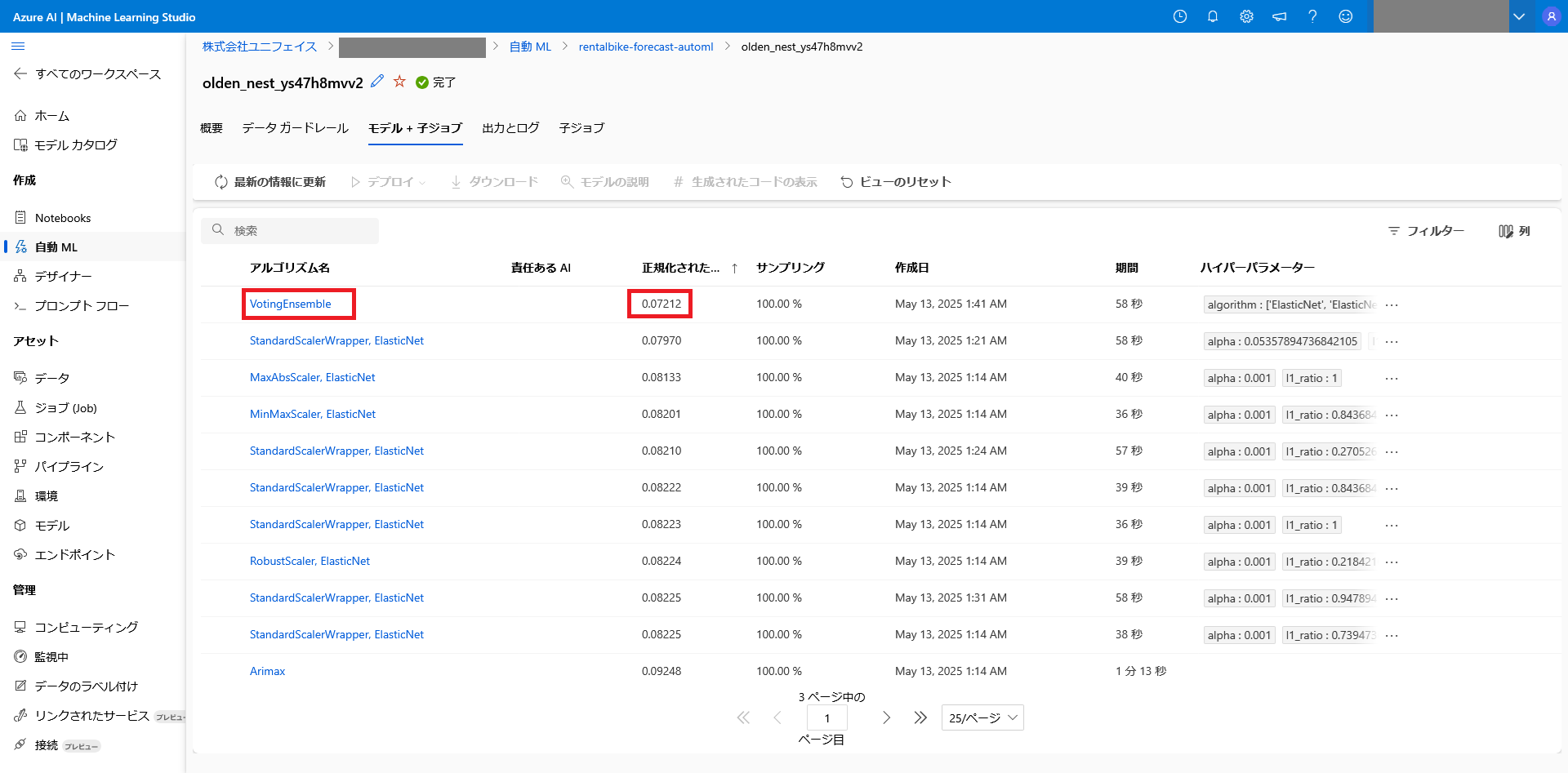
完成したモデルは、AutoML ジョブの「モデル+子ジョブ」タブを選択することで確認出来ます。
AutoML では、様々なアルゴリズムを用いてモデルを作成し、最終的にもっとも予測精度が高かったものを予測モデルとして採用します。
予測精度は「正規化された平均平方二乗誤差」の値が最も0に近かったモデルが高精度なモデルとなります。(予測に使用するアルゴリズムによって異なる。)
今回最も精度の高かった「VotingEnsemble」のモデルを見てみましょう。
(VotingEnsemble は様々なモデルをかけ合わせたモデルで、一番最後に作成される)
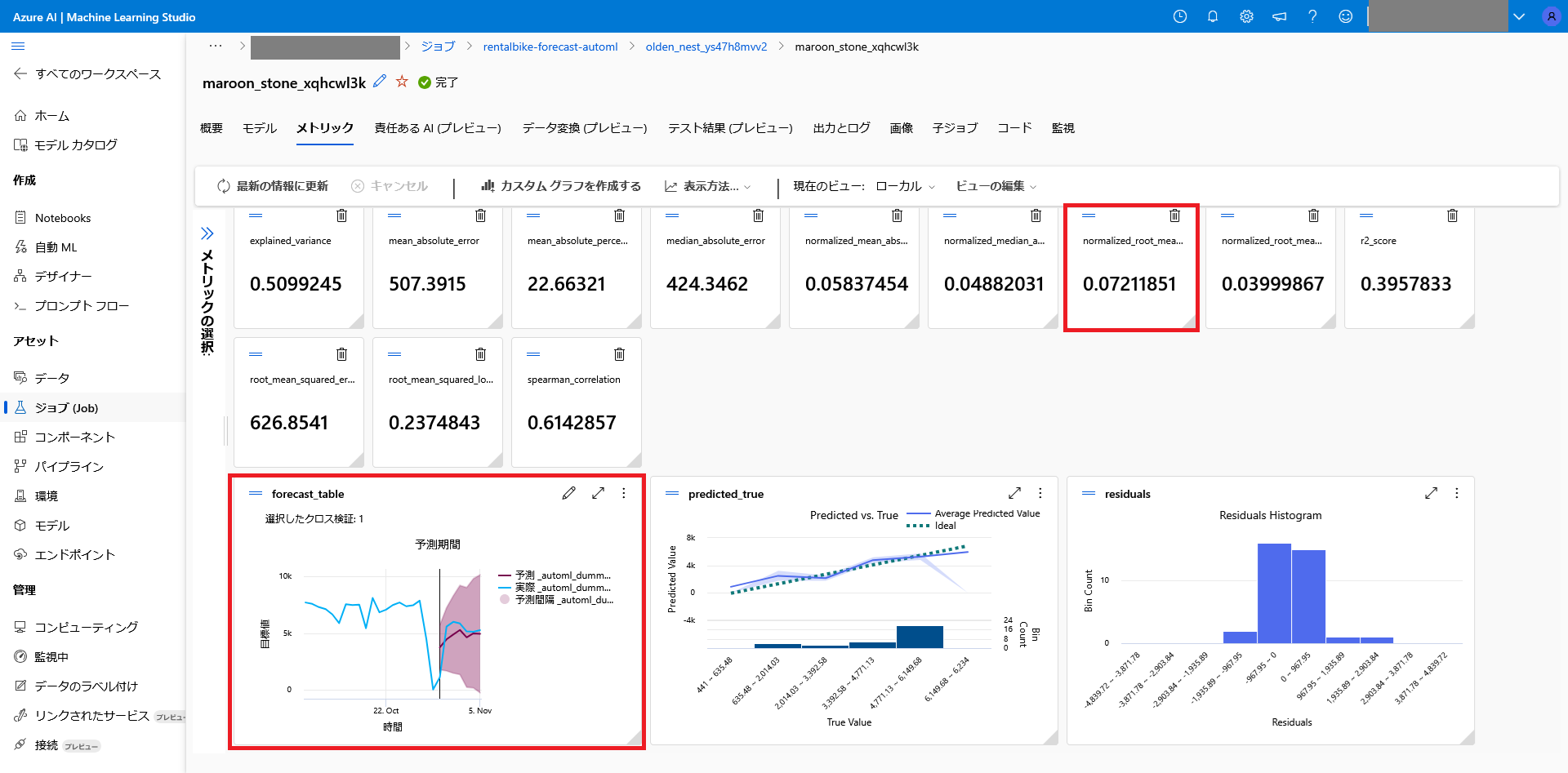
モデルの詳細はメトリックタブから確認します。
各項目の詳細は省略しますが、回帰や分類タスク、時系列予測等、タスクによって重要な指標は異なります。
モデルの改善は、目的の指標が改善されるようにデータの前処理や、使うデータの選定など、多岐にわたりますが、何かを変更してモデルを作成し、メトリックページで結果を確認するという形になります。
ちなみに、作成したモデルは登録することで、デプロイが可能になり、Web上で予測可能なエンドポイントを作成するなども簡単に実施できます。
終わりに
以上でモデルの作成を行う事が出来ました。
AutoMLは少ない設定で面倒な前処理を自動化し、多くのアルゴリズムの中から最も精度の高いモデルを作成してくれる便利な機能です。
しかし、その裏側で何が行われているのかを理解することは、モデルをさらに改善していくうえで欠かせません。モデルの構築自体は慣れてしまえば比較的簡単ですが、そこから先の改善は根気と工夫が求められる作業です。
たとえば、特徴量ごとの重要度を確認することで、どのデータが予測に強く影響しているのかを把握できます。それが業務的な観点から妥当であるかを検証し、さまざまな角度から分析を進めることで、新たな発見やさらなる精度向上につながるかもしれません。
AutoMLの力を活かしつつ、自らの知見を重ねていくことで、より実用的で価値のあるモデル開発につながるはずです。